币灵灵财经 2024-11-23 05:13 821
 图片来源:由无界AI生成
图片来源:由无界AI生成
DatologyAI 成立于 2023 年,在今年初宣布获得 1165 万美元种子轮融资后,刚刚宣布获得 Felicis 领投的 4600 万美元 A 轮融资,其它投资者包括 Radical Ventures、Amplify Partners、Elad Gil、M12 和 Alexa Fund。

创始团队包括前 DeepMind和 Meta AI 研究员 Ari Morcos、前 Twitter 工程主管 Bogdan Gaza 以及前 MosaicML 数据研究主管 Matthew Leavitt。
DatologyAI 目前团队拥有 11 名员工,其目标是减少数据管理中所需的人工决策量(这些决策往往可能存在偏见或耗时)。

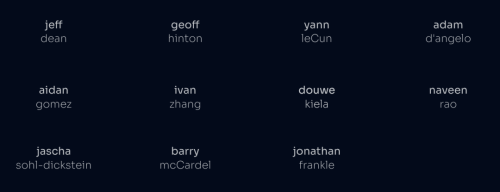
DatologyAI 早期知名天使投资人包括:谷歌首席科学家 Jeff Dean、AI 教父 Geoffrey Hinton、Meta 首席 AI 科学家 Yann LeCun、Quora 创始人& OpenAI 董事会成员 Adam D'Angelo、Cohere联合创始人 Aidan Gomez 和 Ivan Zhang、Contextual AI 创始人 Douwe Kiela、AI 副总裁 Naveen Rao 以及扩散模型发明者之一 Jascha Sohl-Dickstein 。
数据质量问题至今没有得到充分解决,是一个严重的疏忽,因为并非所有数据都是一样的,以正确的方式使用正确的数据训练模型可以对生成的模型产生巨大的影响。这不仅仅是性能的问题。

根据德勤的一项调查中,40% 的公司表示,与数据相关的挑战(包括彻底准备和清理数据)是阻碍其 AI 计划的首要问题之一。另一项针对数据科学家的民意调查发现,科学家大约 45% 的时间花在数据准备任务上,例如“加载”和清理数据。
改进训练数据意味着改进:
通过确定要训练的正确数据以及呈现这些数据的正确方式来解决这个问题,特别是在面对 PB 级未标记数据时,是一个非常具有挑战性且成本高昂的问题,需要专门的专业知识。但解决这个问题的好处是巨大的,它可以说是当今 AI 研究中最重要的主题之一。

DatologyAI 认为,制定 AI 利用标准的公司需要根据自己的专有数据训练自己的模型。其中许多公司拥有 PB 或更多的未标记且通常是非结构化的数据 - 如此之多,以至于他们无法对所有这些数据进行训练,即使他们愿意,因为它很快就会变得成本高昂(假设你甚至可以访问足够的计算!) 。
因此,标准做法是简单地随机选择数据的子集。与深度学习的大多数其他领域不同,这种实践的创新相对较少被采用。这是有问题的,因为对数据的随机子集进行训练有很多很多问题:
底线是:使用错误的数据进行训练会导致模型更差,训练成本更高。但这仍然是标准做法。DatologyAI 利用并执行最先进的研究来管理从 Blob 存储中的数据到用于训练代码的数据加载器的整个过程。客户可以部署到自己的基础设施(本地或通过 VPC),以确保客户数据永远不会面临风险。
区别于与其他数据管理初创公司更实际的方法。其他数据管理初创公司中,员工手动查看客户的私人数据以找出存在差距的地方,DataologyAI 则使用算法自动确定模型需要多少数据才能理解某个概念。
例如,模型需要更多复杂概念(例如狗,外观各异)的示例,而不是简单概念(例如大象,它们看起来相对相似)来理解它们。这些算法还确保模型能够看到足够多的罕见“边缘情况”,并且在训练过程中将数据划分为更易于管理的块。相关环节包括:
目前,DatologyAI 可扩展到 PB 级数据,并支持任何数据模式,无论数据是文本、图像、视频、音频、表格还是基因组或地理空间数据等更奇特的模式。

天使投资者 Yann LeCun 表示,模型的好坏取决于它们所训练的数据,但在数十亿或数万亿个示例中识别正确的训练数据是一个极具挑战性的问题。Ari 和他在 DatologyAI 的团队是解决这个问题的世界专家,相信他们正在构建的产品旨在为任何想要训练模型的人提供高质量的数据管理,这对于帮助 AI 发挥作用至关重要。
Reference:
https://www.datologyai.com/post/datologyai-raises-46m-series-a
https://techcrunch.com/2024/02/22/datologyai-is-building-tech-to-automatically-curate-ai-training-data-sets/
热门文章
为华为手机提供摄像头模组?欧菲光董事长回应
萨尔瓦多比特币浮盈8300万美元!Tim Draper:将成最富裕国家之一
大模型独角兽“智谱 AI”正以200亿元估值进行新一轮融资,此前阿里腾讯等已投资25亿
跨境理财通2.0正式起航 个人投资者额度提高到300万元
9月8日涨停复盘:捷荣技术8天7板 华映科技7天6板
又一城缩减住宅限购范围!已有7个省会城市全面取消限购
Voyager赔偿用户需再等!清算计划修正版待法院批准才能分配代币
5.24 是多还是空 我们该如何抉择?
3年内禁止参加军队采购!奥维通信围标串标被罚 影响几何?
未来健康获罗斯柴尔德家族1亿美金投资,与国际NMN医药集团合作打造全球首创NMN期货产品