币灵灵财经 2024-11-20 04:21 929
中金公司研报指出,2月15日,OpenAI发布最新视频生成模型Sora,能够生成长达一分钟的分辨率为1920*1080的高质量视频,在生成时长和生成质量上较其他现有模型和产品实现了明显突破。
中金认为,Sora实现了AI+视频场景的效果突破,通过借助Transformer架构展现了优异的可拓展性(Scalable)。展望未来,我们判断基于Transformer架构的大模型有望在更多模态领域实现复刻,看好多模态领域技术进展。
以下为其核心观点:
延续DiTs架构,Sora实现高质量长视频生成。根据技术报告,Sora延续DiTs架构,随训练计算量提升而展现出显著的生成能力提升(Scalable)。相较先前模型,我们认为其最为突出的创新之处在于:1)LDM自编码器实现时间维度压缩,使得长视频生成成为可能;2)直接对LDM中潜视频进行图块化处理并直接使用Transformer建模,解除输入格式限制的同时,能够创新性地实现任何像素和长宽比视频的生成;3)我们判断其训练数据集中可能包含带有物理信息的合成数据,从而使模型展现出对物理信息的初步理解能力;4)复用DALL·E 3的重标注技术,对视频数据生成高质量文字标注,借助GPT对提示词进行扩展,提升生成效果。
技术基础一:扩散模型是当前图片/视频生成的主要技术路线。扩散模型(Diffusion model)通过神经网络(主要是U-Net)从纯噪声图像中学习去噪过程,从而通过给定噪声来完成图像生成任务。潜在扩散模型(Latent diffusion model)通过降维进一步提升了训练效率并降低训练成本,成为图片生成的主要技术路线。在预训练的图片生成模型基础上,学界提出生成关键帧并在时序上实现对齐即可将图片生成模型转化为视频生成模型,但这类模型存在生成时长短、稳定性差等劣势。
技术基础二:Transformer架构的引入使扩散模型能够实现规模效应。DiTs(Diffusion transformer)将先前扩散模型的骨干U-Net卷积网络替换为可伸缩性更强的Transformer,从而能够实现更强的可拓展性,即能够通过增加参数规模和训练数据量来快速提升模型的性能表现,模型在图片生成任务上表现优异。W.A.L.T.首次将Transformer架构引入视频生成模型,使用窗口注意力降低了对算力的需求,并展现了良好的视频生成能力。
我们认为Sora实现了AI+视频场景的效果突破,通过借助Transformer架构展现了优异的可拓展性(Scalable)。展望未来,我们判断基于Transformer架构的大模型有望在更多模态领域实现复刻,看好多模态领域技术进展。
风险
技术进展不及预期;应用落地不及预期;行业竞争加剧。
热门文章
为华为手机提供摄像头模组?欧菲光董事长回应
萨尔瓦多比特币浮盈8300万美元!Tim Draper:将成最富裕国家之一
大模型独角兽“智谱 AI”正以200亿元估值进行新一轮融资,此前阿里腾讯等已投资25亿
跨境理财通2.0正式起航 个人投资者额度提高到300万元
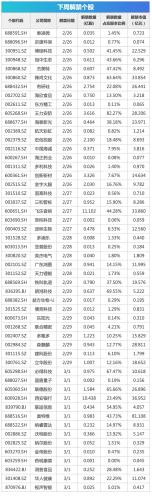
9月8日涨停复盘:捷荣技术8天7板 华映科技7天6板
又一城缩减住宅限购范围!已有7个省会城市全面取消限购
Voyager赔偿用户需再等!清算计划修正版待法院批准才能分配代币
5.24 是多还是空 我们该如何抉择?
3年内禁止参加军队采购!奥维通信围标串标被罚 影响几何?
未来健康获罗斯柴尔德家族1亿美金投资,与国际NMN医药集团合作打造全球首创NMN期货产品